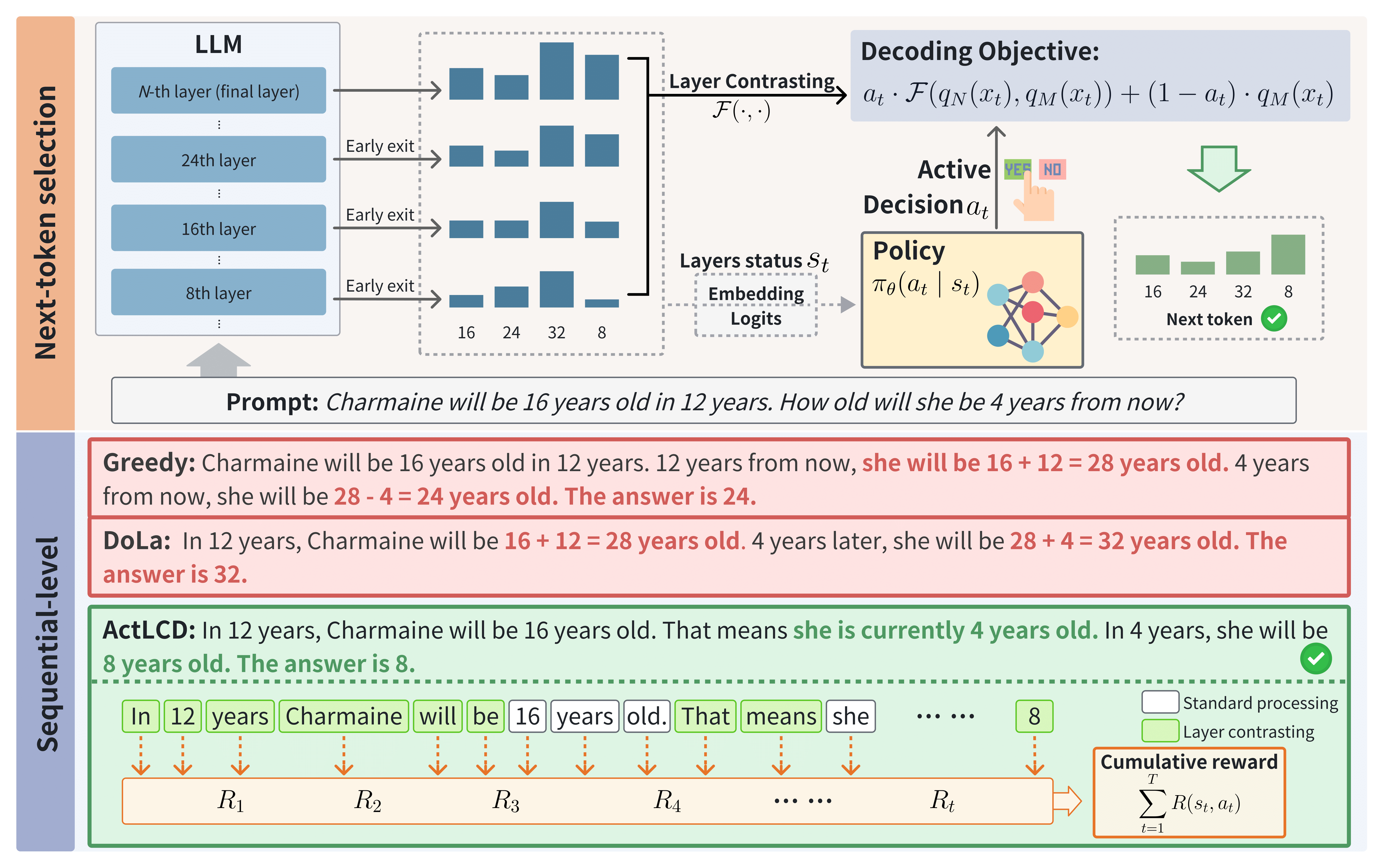
Across 5 benchmarks and multiple LLMs
Recent decoding methods improve the factuality of large language models (LLMs) by refining how the next token is selected during generation. These methods typically operate at the token level, leveraging internal representations to suppress superficial patterns. Nevertheless, LLMs remain prone to hallucinations, especially over longer contexts. In this paper, we propose Active Layer-Contrastive Decoding (ActLCD), a novel decoding strategy that actively decides when to apply contrasting layers during generation. By casting decoding as a sequential decision-making problem, ActLCD employs a reinforcement learning policy guided by a reward-aware classifier to optimize factuality beyond the token level.
Our experiments demonstrate that ActLCD surpasses state-of-the-art methods such as SLED and DoLa across open-domain, long-form, chain-of-thought, and domain-specific code benchmarks., showcasing its effectiveness in mitigating hallucinations in diverse generation scenarios.
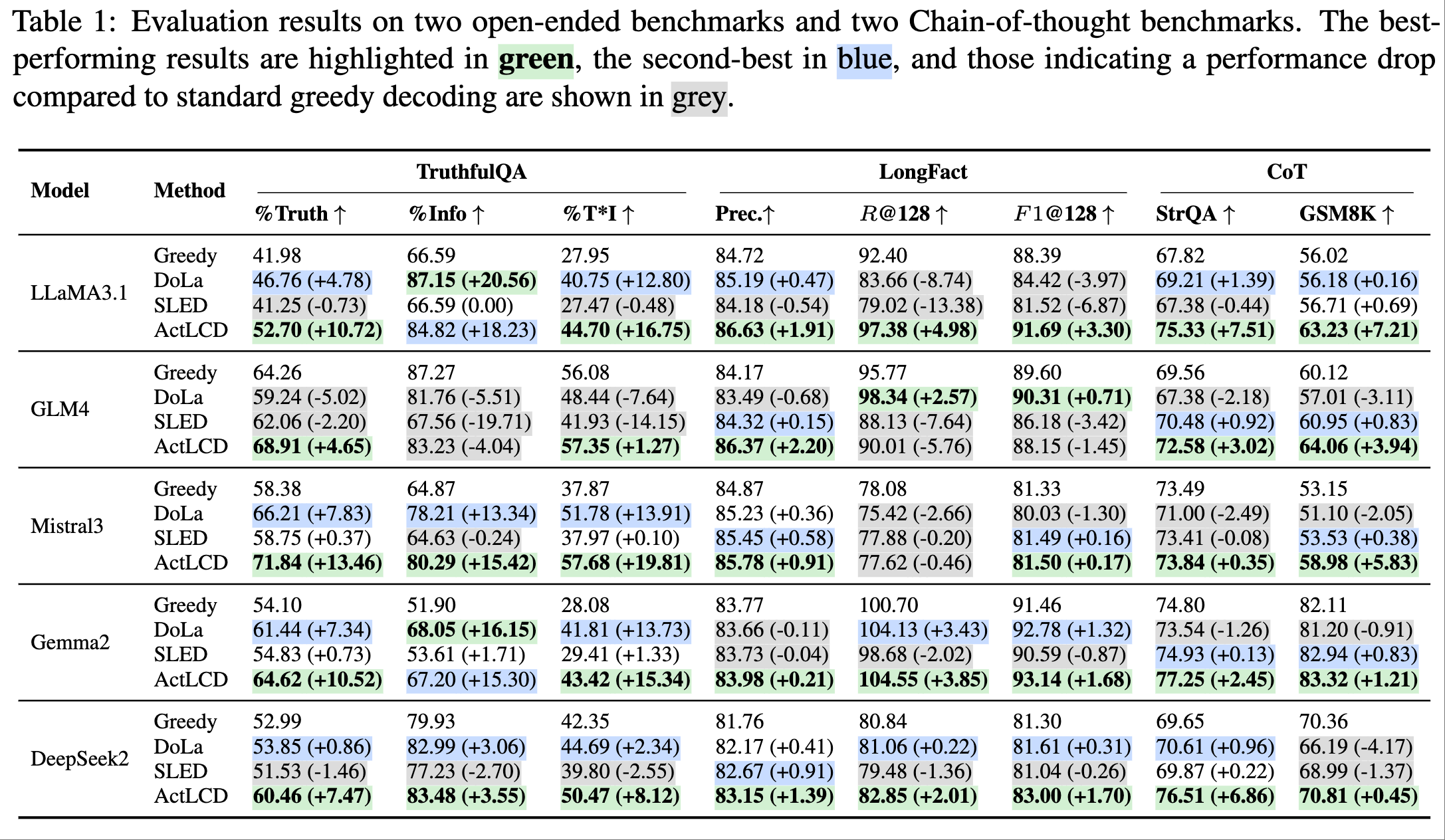
Results overview across TruthfulQA, LongFact, StrategyQA, GSM8K, and package hallucination.

Greedy correctly computes the initial toy count but then “forgets” that value later in its reasoning, resulting in the incorrect answer. Whereas SLED and DoLa misinterpret the toys needed at the beginning, they subsequently build an entire chain of reasoning on this false assumption, resulting in a significantly incorrect answer. This exemplifies a phenomenon known as “hallucination nowballing”, where early mistakes cascade into increasingly severe errors. Such missteps may be due to the side effect of layer contrasting that forces LLMs to interpret longer sentences, potentially leading to fundamental misunderstandings. In contrast, ActLCD selectively activates layer contrasting to leverage latent knowledge in deep layers, fostering a coherent logical thought chain that yields the affirmative answer.
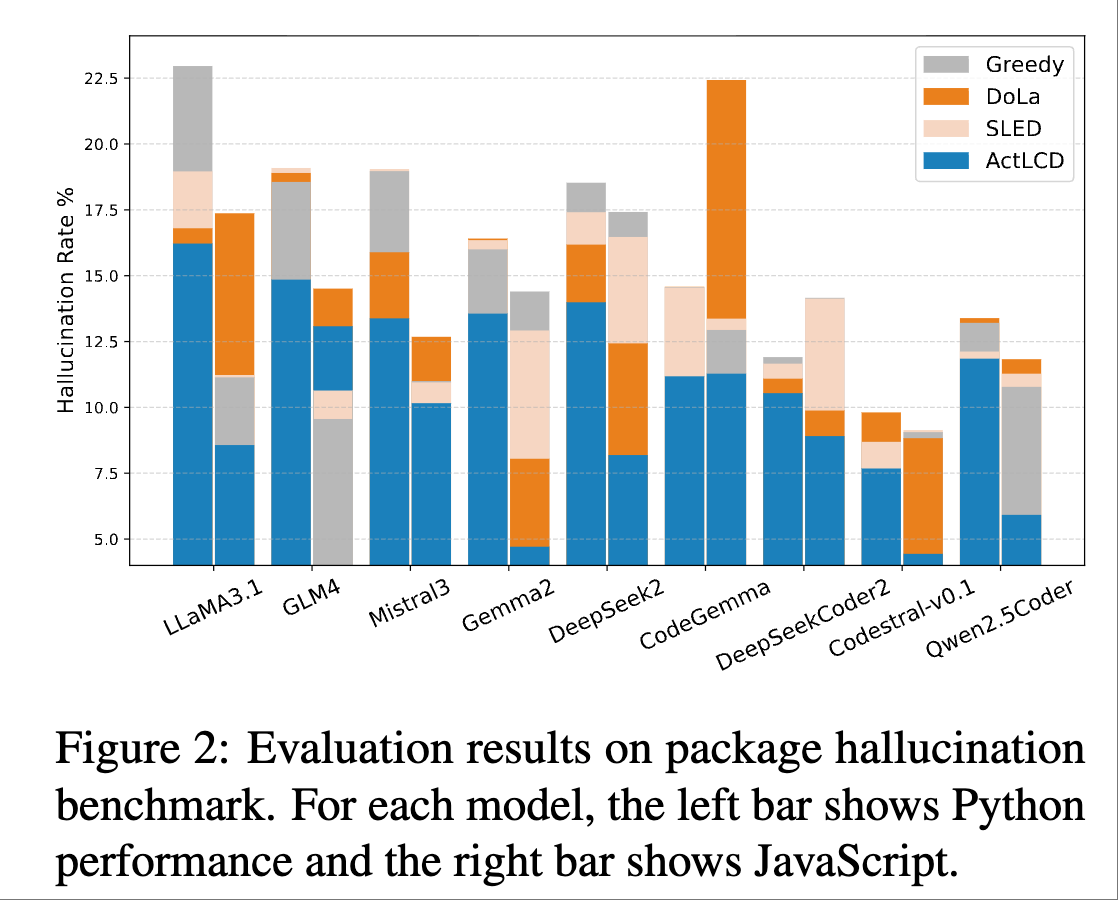
ActLCD significantly reduced package hallucination in both Python and JavaScript. A key challenge in this benchmark is that models must generate multiple package names, where one hallucinated package can compromise the entire response. ActLCD’s dynamic contrastive mechanism is especially beneficial for this context.
Representative decoding and factuality works:
@article{zhang2025active,
title={Active Layer-Contrastive Decoding Reduces Hallucination in Large Language Model Generation},
author={Zhang, Hongxiang and Chen, Hao and Chen, Muhao and Zhang, Tianyi},
journal={arXiv preprint arXiv:2505.23657},
year={2025}
}